Audio
dcase_util.containers.AudioContainer is data container for multi-channel audio. It reads and writes many
formats (e.g. WAV, FLAC, OGG, MP3, M4A, WEBM). Downloading audio content directly from Youtube is also supported.
Creating container
Generating two-channel audio:
fs = 44100
t = numpy.linspace(0, 2, 2 * fs, endpoint=False)
x1 = numpy.sin(220 * 2 * numpy.pi * t)
x2 = numpy.sin(440 * 2 * numpy.pi * t)
audio_container = dcase_util.containers.AudioContainer(data=[x1, x2], fs=fs, channel_labels=['left', 'right'])
Show container information:
# AudioContainer :: Class
# Sampling rate : 44100
# Channels : 2
# Labels :
# [0] : left
# [1] : right
# Duration
# Seconds : 2.00 sec
# Milliseconds : 2000.00 ms
# Samples : 88200 samples
Loading and Saving
Loading audio file:
audio_container = dcase_util.containers.AudioContainer().load(
filename=dcase_util.utils.Example.audio_filename()
)
Show container information:
# AudioContainer :: Class
# Filename : acoustic_scene.flac
# Synced : Yes
# Sampling rate : 44100
# Channels : 2
# Duration
# Seconds : 10.00 sec
# Milliseconds : 10000.02 ms
# Samples : 441001 samples
Loading audio content from Youtube:
audio_container = dcase_util.containers.AudioContainer().load_from_youtube(
query_id='2ceUOv8A3FE',
start=1,
stop=5
)
Focus segment
The container has focus mechanism to flexibly capture only part of the audio data while keeping full audio signal intact. Focusing can be done based on time (in seconds, if time resolution is defined), or based on sample ids. Focusing can be done to single channel or mixdown (mono) channels. Audio containers content can be replaced with focus segment by freezing it.
Using focus to get part data between 0.5 sec and 1.0 sec:
print(audio_container.set_focus(start_seconds=0.5, stop_seconds=1.0).get_focused().shape)
# (2, 22050)
Using focus to get part data starting 5 sec with 2 sec duration:
print(audio_container.set_focus(start_seconds=5, duration_seconds=2.0).get_focused().shape)
# (2, 88200)
Using focus to get part data starting 5 sec with 2 sec duration, mixdown of two stereo channels:
print(audio_container.set_focus(start_seconds=5, duration_seconds=2.0, channel='mixdown').get_focused().shape)
# (88200,)
Using focus to get part data starting 5 sec with 2 sec duration, left of two stereo channels:
print(audio_container.set_focus(start_seconds=5, duration_seconds=2.0, channel='left').get_focused().shape)
# (88200,)
Using focus to get part data starting 5 sec with 2 sec duration, seconds audio channel (indexing starts from 0):
print(audio_container.set_focus(start_seconds=5, duration_seconds=2.0, channel=1).get_focused().shape)
# (88200,)
Using focus to get part data between samples 44100 and 88200:
print(audio_container.set_focus(start=44100, stop=88200).get_focused().shape)
# (2, 44100)
Resetting focus and accessing full data matrix:
audio_container.reset_focus()
print(audio_container.get_focused().shape)
# (2, 441001)
Using focus to get part data starting 5 sec with 2 sec duration, and freeze this segment
audio_container.set_focus(start_seconds=5, duration_seconds=2.0).freeze()
print(audio_container.shape)
# (2, 88200)
Frames and Segments
Splitting audio signal into overlapping frames (200ms frame length with 50% overlap):
print(audio_container.frames(frame_length_seconds=0.2, hop_length_seconds=0.1).shape)
# (8820, 99)
Splitting audio signal into non-overlapping segments (1 sec):
data, segment_meta = audio_container.segments(segment_length_seconds=1.0)
print(len(data))
# 10
print(data[0].shape)
# (44100,)
segment_meta.log_all()
[I] MetaDataContainer :: Class
# Items : 10
# Unique
# Files : 0
# Scene labels : 0
# Event labels : 0
# Tags : 0
#
# Meta data
# Source Onset Offset Scene Event Tags Identifier
# -------------------- ------ ------ --------------- --------------- --------------- -----
# - 0.00 1.00 - - - -
# - 1.00 2.00 - - - -
# - 2.00 3.00 - - - -
# - 3.00 4.00 - - - -
# - 4.00 5.00 - - - -
# - 5.00 6.00 - - - -
# - 6.00 7.00 - - - -
# - 7.00 8.00 - - - -
# - 8.00 9.00 - - - -
# - 9.00 10.00 - - - -
Splitting audio signal into non-overlapping segments (1 sec) while avoiding certain regions of the signal:
data, segment_meta = audio_container.segments(
segment_length_seconds=1.0,
skip_segments=dcase_util.containers.MetaDataContainer(
[
{
'onset': 3.5,
'offset': 6.5
}
]
)
)
segment_meta.log_all()
# MetaDataContainer :: Class
# Items : 6
# Unique
# Files : 0
# Scene labels : 0
# Event labels : 0
# Tags : 0
#
# Meta data
# Source Onset Offset Scene Event Tags Identifier
# -------------------- ------ ------ --------------- --------------- --------------- -----
# - 0.00 1.00 - - - -
# - 1.00 2.00 - - - -
# - 2.00 3.00 - - - -
# - 6.50 7.50 - - - -
# - 7.50 8.50 - - - -
# - 8.50 9.50 - - - -
#
Splitting audio signal into non-overlapping segments (1 sec) from defined regions while avoiding certain regions of the signal:
active_segments = dcase_util.containers.MetaDataContainer(
[
{
'onset': 0.0,
'offset': 5.0,
},
{
'onset': 8.0,
'offset': 13.0,
},
]
)
data, segment_meta = audio_container.segments(
segment_length_seconds=1.0,
skip_segments=dcase_util.containers.MetaDataContainer(
[
{
'onset': 3.5,
'offset': 6.5
}
]
)
)
segment_meta.log_all()
# MetaDataContainer :: Class
# Items : 8
# Unique
# Files : 0
# Scene labels : 0
# Event labels : 0
# Tags : 0
#
# Meta data
# Source Onset Offset Scene Event Tags Identifier
# -------------------- ------ ------ --------------- --------------- --------------- -----
# - 0.00 1.00 - - - -
# - 1.00 2.00 - - - -
# - 2.00 3.00 - - - -
# - 6.50 7.50 - - - -
# - 8.00 9.00 - - - -
# - 9.00 10.00 - - - -
# - 10.00 11.00 - - - -
# - 11.00 12.00 - - - -
#
Processing
Normalizing audio:
audio_container.normalize()
Resampling audio to target sampling rate:
audio_container.resample(target_fs=16000)
Visualizations
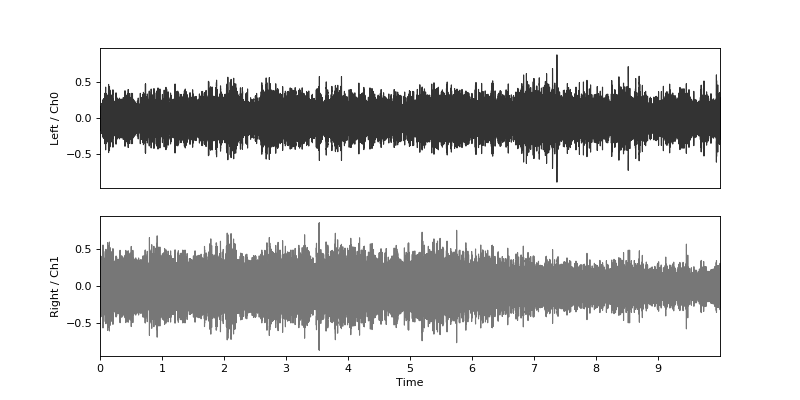
Plot waveform:
audio_container.plot_wave(channel_labels=['Left', 'Right'], color=['#333333', '#777777'])
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
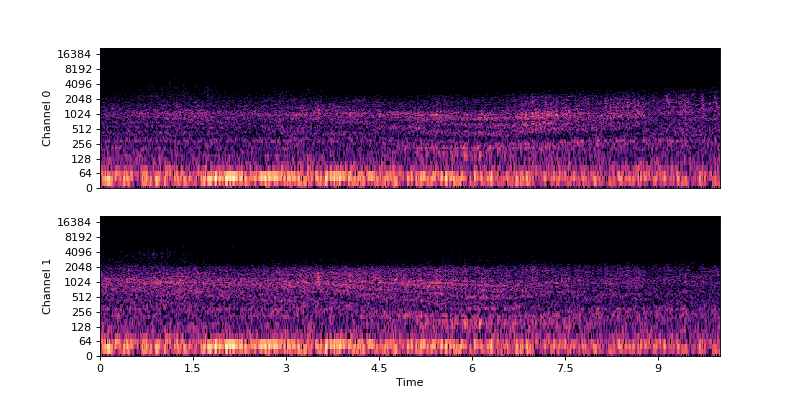
Plot spectrogram:
audio_container.plot_spec()
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
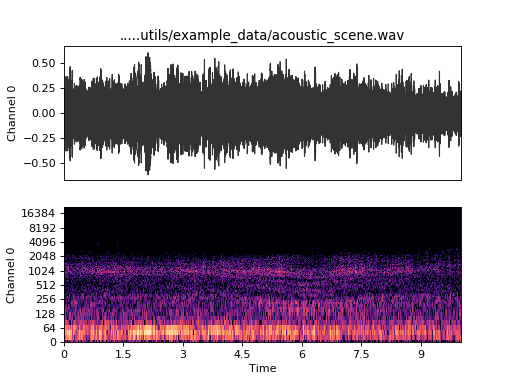
Plot waveform and spectrogram together:
plt.figure()
plt.subplot(2, 1, 1)
audio_container.plot(plot_type='wave', plot=False, show_filename=False, show_xaxis=False)
plt.subplot(2, 1, 2)
audio_container.plot(plot_type='spec', plot=False, show_filename=False, show_colorbar=False)
plt.show()
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
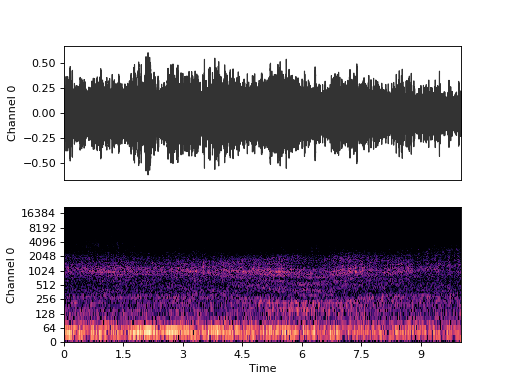
Or with single command:
audio_container.plot(plot_type='dual')
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}